
¿Podemos conocer la velocidad a la que emergerán las innovaciones del futuro?
Jon Mikel Zabala Iturriagagoitia
En plena ebullición de la inteligencia artificial y el deep tech, conocer dónde y a qué ritmo “se cocina” la ciencia ya no es algo solo para geeks, sino que representa una información estratégica para empresas, inversores y responsables de política pública (economía, universidades, ciencia y tecnología, industria). En este sentido, un clásico lo representan los informes que la consultora Gartner publica de manera anual y en los que proporciona un mapa que identifica las áreas de innovación con mayor potencial.
Un informe reciente de BBVA Research presenta una propuesta sencilla pero muy poderosa debido a su escalabilidad; analizar los preprints publicados en ArXiv. ArXiv es un repositorio de acceso abierto, donde los científicos comparten versiones preliminares todavía no revisadas por pares (llamados preprints) de sus artículos, para difundir rápidamente sus resultados y recibir comentarios sobre los mismos, antes de que estos hayan sido publicados formalmente en revistas científicas, de manera que puedan mejorar la calidad de dichos artículos.
De cara a poder identificar potenciales vías de desarrollo futuro (o de innovación), el análisis de los preprints de ArXiv ofrece tres grandes ventajas:
– Tiene una cobertura masiva y gratuita: el 91% de todos los preprints registrados en el mundo a fecha de marzo de 2025 están disponibles en ArXiv. Cinco millones de usuarios acceden cada mes sin coste alguno a dicha evidencia científica.
– Cuenta con una alta frecuencia y granularidad: a diferencia de las patentes o de las estadísticas de I+D (trimestrales o anuales), los preprints aparecen a diario, por lo que se pueden identificar las tendencias casi al instante.
– Genera un efecto altavoz: publicar un artículo en ArXiv añade, de media, 21 citas extra en los primeros cinco años de la publicación del artículo. Por ejemplo, durante la COVID-19, la difusión rápida de preprints a través de ArXiv sirvió para acelerar la comunicación científica y el desarrollo de las vacunas.
El equipo de BBVA Research ha rastreado 129 categorías temáticas (40 de ciencias de la computación, 51 de física y 38 de matemáticas/estadística) desde 1991, empleando técnicas de web scraping y de procesamiento natural del lenguaje. Ello no solo les permite contabilizar los nuevos trabajos subidos a ArXiv en cada área temática, sino también analizar el tipo de progreso tecnológico que se produce en cada una de ellas. Los resultados obtenidos ofrecen una serie de conclusiones muy llamativas.
En primer lugar, se observa cómo en 2010 la informática suponía menos del 10 % de todos los preprints, mientras que en 2025 roza el 50 %, desbancando a la física como disciplina científica reina. En segundo lugar, y dentro de la informática, la inteligencia artificial absorbe ya el 70% de la producción, con campos crecientes como el aprendizaje automático, la visión por computador, el procesamiento natural del lenguaje o la robótica. Esta relevancia creciente de la informática como campo científico comienza en 2014, con hitos como el dataset COCO o la arquitectura Inception, y se dispara tras la llegada de los Transformers en 2017 y los grandes modelos de lenguaje en el periodo 2020-2024. Por último, a pesar de que la criptografía y la ciberseguridad no hayan crecido en términos relativos, su importancia se mantiene en el tiempo, indicando el rol central que tiene la protección de los datos empleados en la generación de modelos cada vez más potentes.
Figura 1. Evolución relativa de las 10 categorías principales de computación en ArXiv
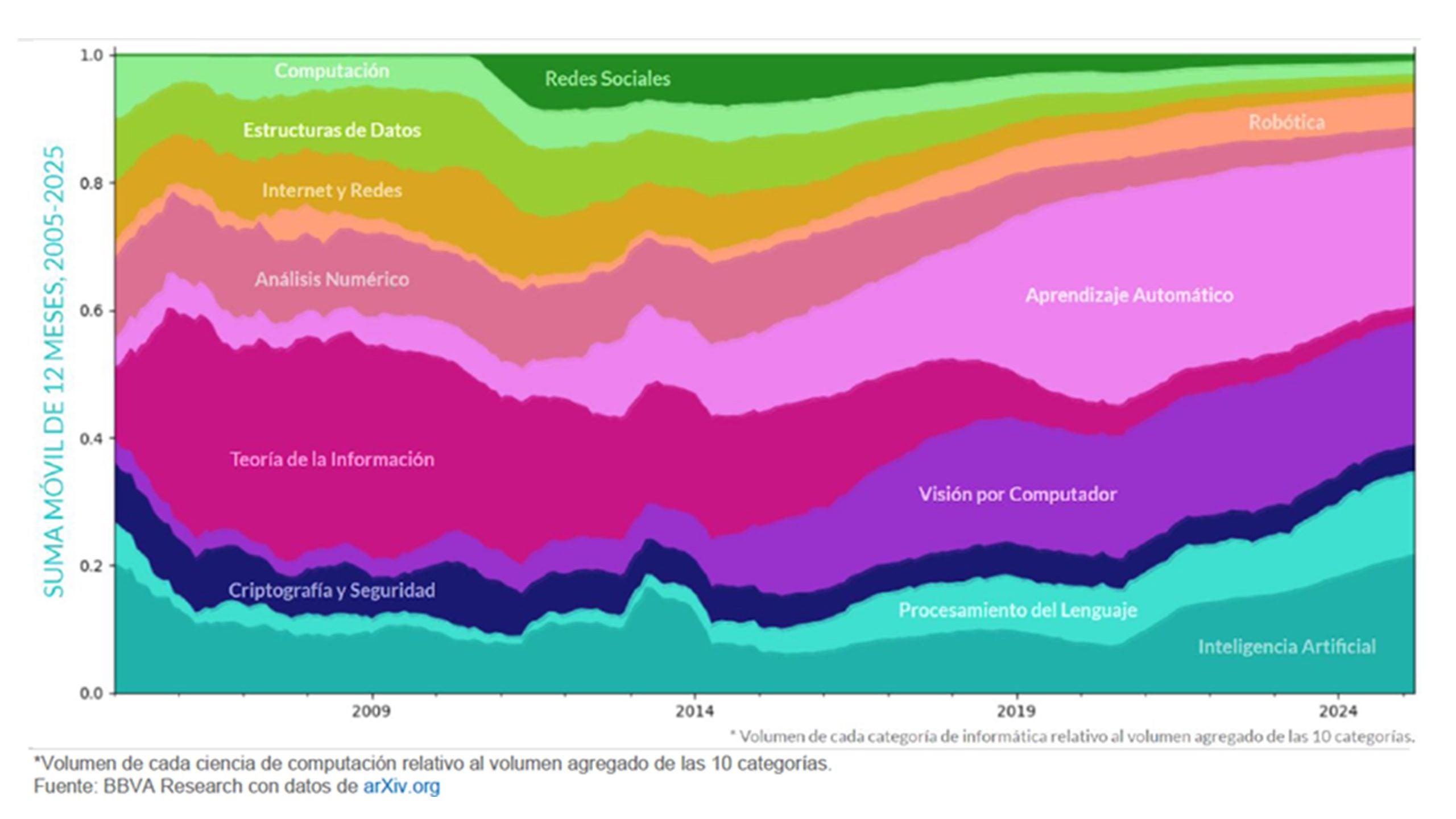
El documento no enumera pronósticos concretos (i.e., “el próximo gran hit será X”), pero sí ofrece pistas sólidas sobre dónde es más probable que aparezcan las disrupciones tecnológicas, extraídas de la pendiente de crecimiento de cada subcampo. En este sentido, se apuntan cuatro posibles direcciones de potencial innovador en un futuro cercano:
– Está creciendo el solapamiento entre visión, audio y procesamiento natural del lenguaje, lo que dará lugar al desarrollo de modelos multimodales, que sean capaces de razonar con imágenes, vídeo y texto de forma unificada.
– Los rápidos avances en aprendizaje por refuerzo están convirtiendo la robótica plenamente autónoma en una opción real, lo que permitirá que se desarrollen robots logísticos e industriales más versátiles. De esta evolución pueden emerger por ejemplo brazos colaborativos capaces de aprender nuevas tareas en horas, drones de inventario que se coordinan entre sí, vehículos móviles que reconfiguran sus rutas en tiempo real y robots de montaje que cambian de producto sobre la marcha sin reprogramación manual.
– Más allá de la robótica, se espera una rápida extensión de la IA a las ciencias sociales, principalmente en áreas como las fintech, la economía comportamental, y las políticas públicas. De esta convergencia pueden surgir innovaciones como asesores financieros autónomos que personalizan inversiones en tiempo real, plataformas digitales que adaptan su oferta a la conducta del usuario, y sistemas regulatorios capaces de detectar riesgos sistémicos o posibles fraudes.
– Desde 2023 se observa un fuerte repunte de investigaciones en computación distribuida (cs.DC) y arquitectura de redes (cs.NI), signo de la carrera por crear hardware y redes a medida para la IA generativa, y por desplegar edge computing, que acerque la potencia de los grandes modelos al propio dispositivo y reduzca la latencia. De esta tendencia pueden surgir innovaciones como aceleradores específicos para IA generativa, interconexiones de alta velocidad, redes definidas por software optimizadas para mover modelos y datos, y plataformas de inferencia-entrenamiento que funcionen de forma segura en móviles, vehículos y sensores industriales.
La metodología que ha empleado BBVA Research podría extenderse, integrando repositorios como SSRN, bioRxiv, Research Square o Preprints.org, de modo que al incorporar economía y ciencias sociales el pulso científico se convierta en un auténtico barómetro para anticipar tendencias macroeconómicas.
Moraleja: “A quien madruga, Dios le ayuda”. En innovación, madrugar es leer los preprints antes que nadie.